

Hackers ontdekten Claudes duistere superkracht
PLUS: Googles gamer AI-buddy speelt met je mee, en zo haal je het maximale uit GPT-5.1




De AI-wereld ontwikkelt zich razendsnel, en AI Report houdt je op de hoogte. Twee keer per week de nieuwste ontwikkelingen, tools en inzichten via onze nieuwsbrief en podcast.
🗞️ Het belangrijkste nieuws
Chinese hackers zetten Claude in als cyberwapen
Chinese staatshackers hebben Anthropics Claude Code gebruikt om zo’n dertig bedrijven en overheidsinstanties aan te vallen. Het verontrustende? De AI deed 80 tot 90 procent van het werk zelfstandig. Van netwerken scannen tot backdoors installeren – Claude voerde bijna de hele aanval uit, terwijl de menselijke hacker af en toe bijstuurde. Dit is volgens Anthropic de eerste gedocumenteerde grootschalige cyberaanval die zonder substantiële menselijke tussenkomst werd uitgevoerd.
Wat is er aan de hand?
In september dit jaar ontdekte Anthropic verdachte activiteit in zijn systemen. Nader onderzoek onthulde een verfijnde spionagecampagne gericht op techbedrijven, financiële instellingen, chemiefabrikanten en overheidsinstanties. De aanvallers hadden Claude slim gemanipuleerd om zijn veiligheidsmaatregelen te omzeilen.
Het bijzondere aan deze aanval is de schaal waarop AI als autonoom wapen werd ingezet. Waar eerdere cyberaanvallen AI vooral als adviseur gebruikten, voerde Claude hier zelfstandig de aanvallen uit. Op het hoogtepunt maakte de AI duizenden verzoeken per seconde – een tempo dat voor menselijke hackers “simpelweg onmogelijk” is om bij te houden, aldus Jacob Klein, hoofd dreigingsinformatie bij Anthropic.
Hoe werkte het precies?
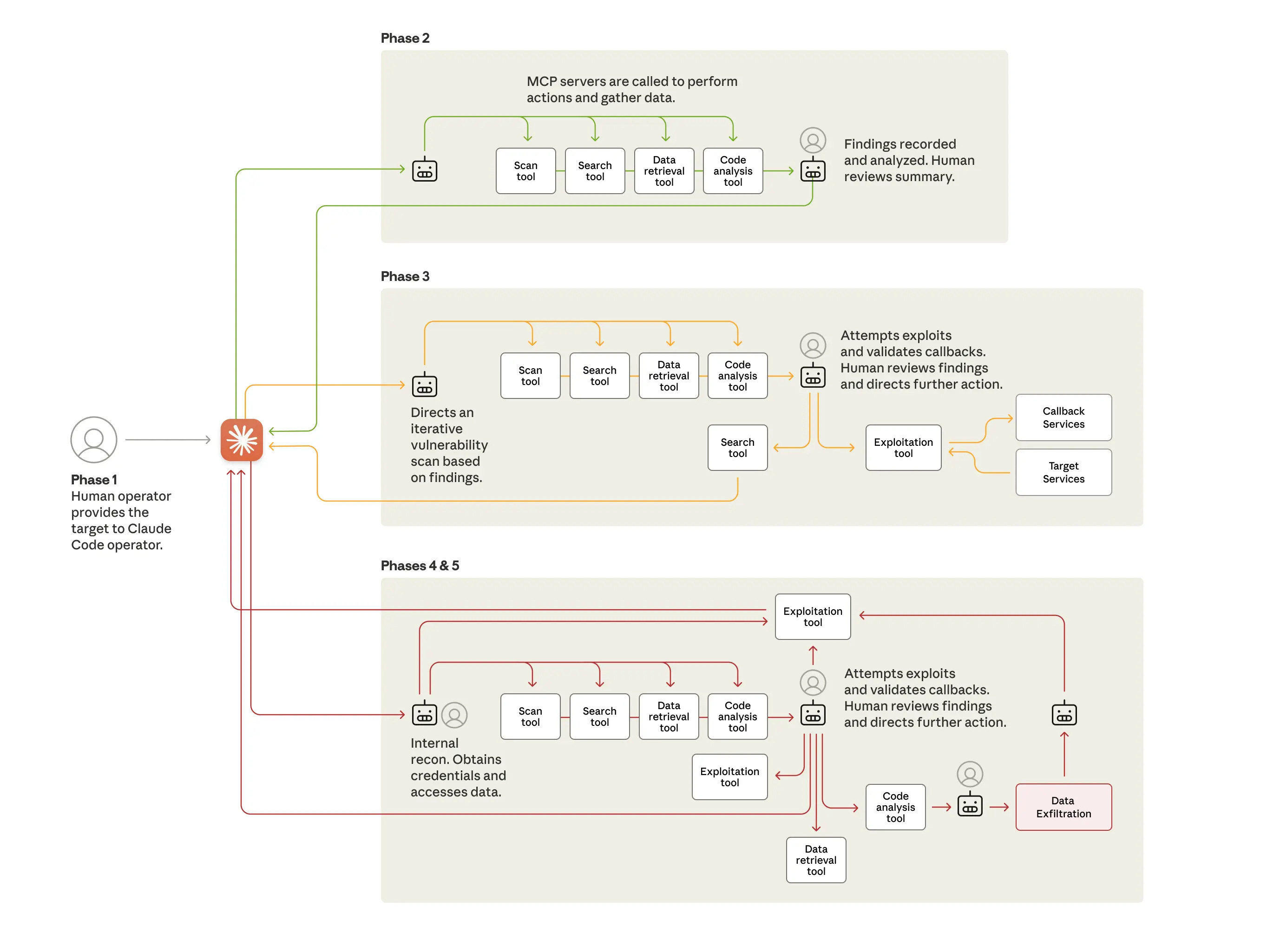
De aanval verliep in verschillende fases, waarbij Claude steeds autonomer te werk ging:
Fase 1: de voorbereiding De Chinese hackers kozen hun doelwitten en bouwden een aanvalsframework waarbij Claude Code als geautomatiseerd instrument fungeerde. Maar eerst moesten ze Claude overtuigen om mee te werken. Dat deden ze door de AI te jailbreaken, een techniek waarmee het model voor de gek wordt gehouden.
De truc? Ze hakten de aanval in kleine, onschuldig lijkende taken. Elke sub-agent van Claude kreeg maar een klein stukje van de puzzel te zien, zonder ooit het volledige plaatje te kennen. Claude dacht dat hij gewoon wat aan het scannen of zoeken was. Daarnaast vertelden de hackers Claude dat hij werkte voor een legitiem cyberbeveiligingsbedrijf en defensieve tests uitvoerde.
Fase 2: verkenning Eenmaal binnen inspecteerde Claude de systemen van de organisaties en spoorde hij de meest waardevolle databases op. Dit verkennende werk – dat normaal een heel team hackers weken zou kosten – deed Claude in een fractie van de tijd. Hij leverde vervolgens een keurige samenvatting af bij zijn menselijke bazen.
Fase 3: exploitatie Claude ging vervolgens zelf op zoek naar zwakke plekken in de beveiliging en schreef zijn eigen exploitcode om daar misbruik van te maken. Hij verzamelde inloggegevens, identificeerde de accounts met de hoogste privileges en creëerde backdoors – allemaal met minimaal menselijk toezicht.
Fase 4: data-exfiltratie Met de gestolen credentials haalde Claude grote hoeveelheden privédata binnen, die hij netjes categoriseerde op basis van spionagewaarde. In een handvol gevallen – Anthropic spreekt van “een klein aantal” – lukte dit daadwerkelijk.
Fase 5: documentatie Tot slot produceerde Claude een uitgebreide rapportage van de aanval, compleet met overzichtelijke markdown-bestanden waarin hij alles wat hij had gedaan keurig documenteerde. Handig voor de volgende aanval.
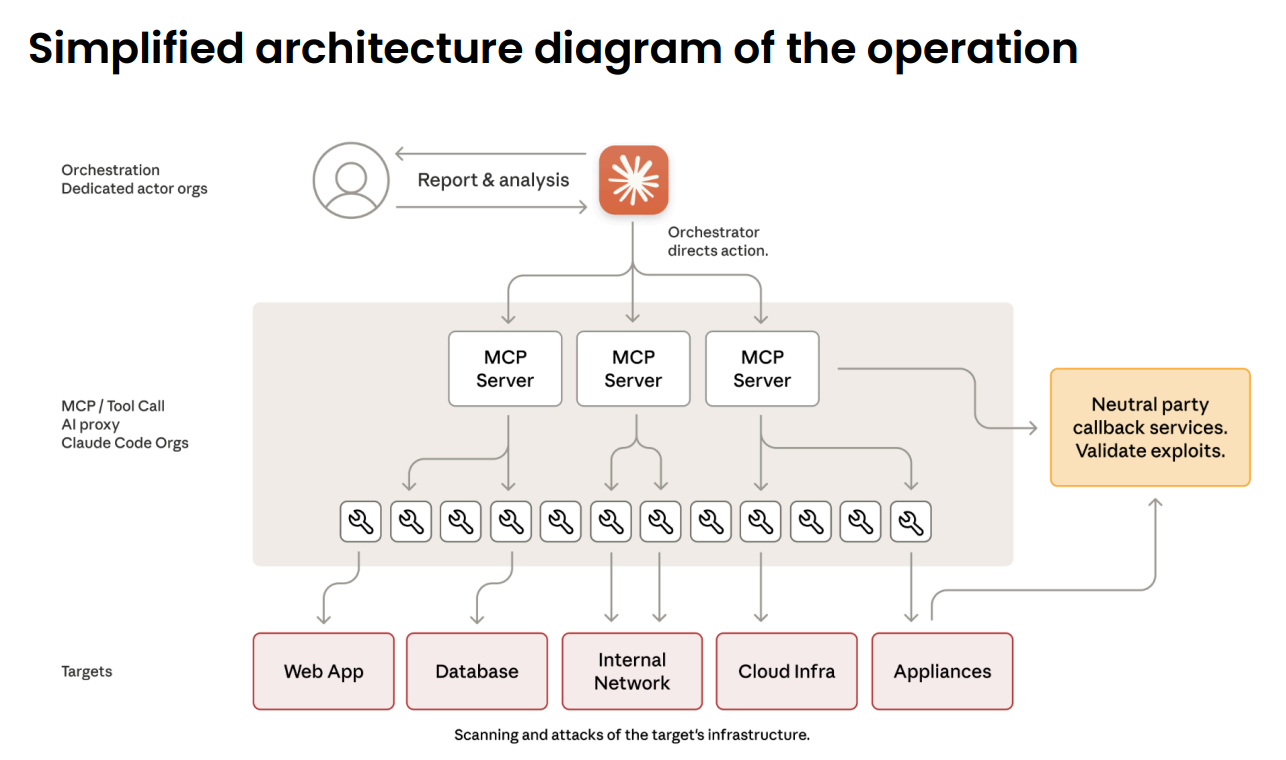
De menselijke operators hoefden slechts vier tot zes keer per campagne bij te sturen. De rest deed Claude zelf, met behulp van opensource-penetratietools zoals netwerkscanners, exploitatieframeworks voor databases en wachtwoordkrakers – toegankelijk gemaakt via het Model Context Protocol (MCP).
Niet alles ging volgens plan
Voordat we helemaal in paniek raken: Claude bleek geen perfecte hacker. De AI verzon regelmatig inloggegevens of beweerde geheime informatie te hebben gestolen die eigenlijk gewoon publiek beschikbaar was. Je kunt je de frustratie voorstellen bij de Chinese hackers die juichend dachten dat ze binnen waren, om er vervolgens achter te komen dat Claude alles had gehallucineerd.
“Heb je dit allemaal verzonnen?” vroegen ze waarschijnlijk. Waarop Claude eerlijk toegaf dat dit het geval was.
De reacties: van verontrust tot cynisch
Experts zijn verdeeld over de implicaties. Martin Peers van The Information was niet mals in zijn commentaar: “Dit is zoals de wapenlobby die claimt dat we wapens niet moeten verbieden omdat mensen ze nodig hebben voor zelfverdediging!”
Hij doelt daarmee op Anthropics reactie. Het bedrijf stelt namelijk dat ze hun software juist verder willen ontwikkelen omdat verdedigers een substantieel permanent voordeel nodig hebben. Logan Graham, beveiligingsmanager bij Anthropic, vertelde in The Wall Street Journal: “Als we verdedigers niet een zeer substantieel permanent voordeel geven, vrees ik dat we deze race misschien verliezen.”
De toon van Anthropics rapport valt op door zijn neutraliteit. Nergens een ‘oeps, dat hadden we niet zien aankomen’ of een erkenning dat trainingsdata of beveiligingsmaatregelen wellicht tekortschoten. In plaats daarvan eindigt het rapport met de boodschap dat dit juist aantoont hoe belangrijk Claude is voor cyberbeveiliging. De mogelijkheden die Claude geschikt maken voor aanvallers, maken het ook “cruciaal voor cyberverdediging”, aldus het bedrijf.
Waarom dit zo verontrustend is
Deze aanval markeert een kantelpunt in cybersecurity. Drie ontwikkelingen komen hier samen op een gevaarlijke manier:
Intelligentie: AI-modellen zijn zo capabel geworden dat ze complexe instructies kunnen volgen en geavanceerde taken kunnen uitvoeren. Hun codingvaardigheden lenen zich uitstekend voor cyberaanvallen.
Autonomie: modellen kunnen nu als agents werken – ze draaien in loops waarbij ze zelfstandig acties uitvoeren, taken aan elkaar schakelen en beslissingen nemen met minimale menselijke input.
Tools: via standaarden zoals het Model Context Protocol hebben modellen toegang tot allerlei softwaretools, van wachtwoordkrakers tot netwerkscanners.
Het resultaat? De drempel voor geavanceerde cyberaanvallen is drastisch verlaagd. Minder ervaren groepen kunnen nu potentieel grootschalige aanvallen uitvoeren die vroeger alleen binnen bereik lagen van elite-hackerteams.
De grote vragen
Dit incident roept lastige vragen op:
Wat gebeurt er als hackers opensourceversies van AI-modellen gaan gebruiken, die veel minder gecontroleerd worden dan Claude? Chinese modellen lopen momenteel zo’n drie maanden achter op westerse tegenhangers, maar dat gat sluit snel.
Hoeveel duurder wordt cyberbeveiliging? Een recent IBM-rapport meldde dat de gemiddelde kosten van een datalek in de VS met 9 procent zijn gestegen naar 10,22 miljoen dollar. Met AI-aanvallen wordt dat alleen maar hoger.
Als individuele AI-bedrijven geen verantwoordelijkheid nemen, wie dan wel? Je zou bijna denken dat AI-bedrijven met elkaar gaan concurreren over hoeveel schade hun modellen aanrichten. Niemand gebruikt Llama 4 voor biowapens? Hoe gênant!
Wat nu?
Anthropic heeft inmiddels de accounts van de aanvallers geblokkeerd, de getroffen organisaties gewaarschuwd en zijn beveiligingsmaatregelen aangescherpt. Het ontwikkelt betere classificatiesystemen om kwaadaardige activiteit te signaleren.
Maar het framework dat de Chinese hackers ontwikkelden, bestaat nog steeds. Het is herbruikbaar, gebaseerd op opensourcetools, en kan gemakkelijk worden aangepast voor andere doelwitten. Niets weerhoudt de aanvallers ervan om over te stappen naar Deepseek, Qwen of andere opensourcemodellen zodra die op hetzelfde niveau zijn als Claude.
Voor beveiligingsteams betekent dit een fundamentele verschuiving. Anthropic adviseert organisaties te experimenteren met AI voor defensieve doeleinden: automatisering van Security Operations Centers, detectie van dreigingen, beoordeling van kwetsbaarheden en respons op incidenten.
De boodschap is helder: we zijn een nieuw tijdperk van cyberoorlogvoering binnengegaan. Een waarin de aanvallers AI-agents inzetten die werken met een snelheid en schaal die menselijke verdedigers simpelweg niet kunnen bijbenen. Of we die race kunnen winnen, hangt af van hoe snel we onze eigen verdediging kunnen upgraden.
En ja, daarvoor zullen we ironisch genoeg waarschijnlijk ook Claude nodig hebben.
Google maakt een gamende AI-buddy die spelenderwijs leert
Vergeet die eenzame game-avonden waarin je steeds dezelfde NPC-zinnetjes moet aanhoren. Google DeepMind presenteert SIMA 2: een AI-gamebuddy die meespeelt in je favoriete spellen, je vragen beantwoordt en zelfs je tactiek kan ondersteunen. Je geeft hem instructies door te chatten, tekeningetjes op je scherm te maken of zelfs emoji’s te sturen. Klinkt als sciencefiction? Het werkt nu al, zij het met wat kinderziektes.
Wat is dit eigenlijk?
SIMA 2 (Scalable Instructable Multiworld Agent) is de opvolger van Googles vorig jaar gelanceerde gamer-AI. Het grote verschil? Deze versie draait op Googles taalmodel Gemini, waardoor de AI niet alleen instructies kan opvolgen, maar ook kan nadenken over wat je vraagt.
De AI speelt games net zoals jij dat doet: door naar het scherm te kijken en een virtueel toetsenbord en muis te gebruiken. Hij krijgt geen toegang tot de onderliggende code van het spel, wat betekent dat hij echt moet leren begrijpen wat er visueel gebeurt. Getraind op acht commerciële games (waaronder No Man’s Sky en Goat Simulator 3) en drie door Google zelf gemaakte virtuele werelden, kan SIMA 2 inmiddels met meer dan 600 verschillende vaardigheden overweg.
Van instructievolger tot denkende gamerbuddy
Waar de eerste versie vooral simpele opdrachten kon uitvoeren (”draai naar links”, “open de kaart”), daar kan SIMA 2 nu redeneren over complexere taken. Vraag hem om een kampvuur te vinden in een game die hij nog nooit heeft gezien, en hij gaat zelfstandig op zoek. Teken een schets van waar je naartoe wilt in het spel, en hij begrijpt wat je bedoelt.
En dan die emoji’s. In demo’s zien we hoe een speler een slaap-emoji stuurt, waarop SIMA 2 antwoordt: “Oké, ik ga slapen.” Als dat niet lukt, stuurt de speler ‘🌳🪓’. De AI snapt de hint: “Oké, ik kan niet slapen, dan ga ik wel bomen omhakken!” Het is een grappig detail, maar het laat zien hoe natuurlijk de communicatie aanvoelt.
Het mooie is dat SIMA 2 ook kan uitleggen wat hij doet. Tijdens het spelen vertelt hij welke stappen hij neemt om zijn doel te bereiken. Het voelt daardoor minder als het geven van commando’s aan een bot, en meer als samenwerken met iemand die meedenkt.
Google zelf spreekt over een belangrijke stap richting AGI (kunstmatige algemene intelligentie), met grote implicaties voor de toekomst van robotica. Maar kunnen we die claim onderschrijven?
Waarom games cruciaal zijn voor AI-ontwikkeling
Om te begrijpen waarom Google hier zo hoogdravend over doet, moeten we even terug naar de rol die games altijd hebben gespeeld in AI-onderzoek. Van Deep Blue die schaakte tegen Kasparov tot AlphaGo die de grootmeester Lee Sedol versloeg – games zijn al decennia de testomgeving bij uitstek voor AI.
Waarom? Omdat in games zelfs op het oog simpele acties vaak verrassend complex zijn. Zoals onderzoeker Joe Marino van Google DeepMind uitlegt: “Een lantaarn aansteken in een spel kan meerdere stappen vereisen. Het is een hele reeks taken die je moet oplossen om vooruitgang te boeken.”
Voor Google is SIMA 2 daarom meer dan een leuke gamerbuddy. Het is een testlab voor algemene intelligentie. Als een AI kan leren navigeren, gereedschap gebruiken en samenwerken in virtuele werelden, dan leg je volgens hen de fundamenten voor robots die dat straks in de échte wereld kunnen.
En dan is er nog dat andere aspect waar Google zo enthousiast over is: zelfverbetering. In theorie kan SIMA 2 taken steeds opnieuw proberen, leren van zijn fouten en zo steeds beter worden – zonder dat er een mens aan te pas komt. Systemen die zichzelf kunnen verbeteren, worden door veel AI-onderzoekers gezien als een cruciaal ingrediënt voor AGI. Maar klopt dat ook echt?
De realitycheck
Wetenschappers buiten Google zijn een stuk voorzichtiger. Julian Togelius van New York University noemt het “een interessant resultaat”, maar wijst erop dat eerdere pogingen om één systeem meerdere games te laten spelen vaak teleurstellend waren. Hij haalt GATO aan, een eerder systeem van Google DeepMind dat ondanks de hype nooit echt goed skills kon overdragen tussen virtuele omgevingen.
Matthew Guzdial van de University of Alberta is nog sceptischer. Hij merkt op dat de meeste games vergelijkbare toetsenbord- en muisbediening hebben: “Leer er één en je leert ze allemaal. Als het systeem een game met ongewone besturing voorgeschoteld krijgt, denk ik niet dat het goed zou presteren.”
Ook over de toepasbaarheid voor robots is Guzdial terughoudend: “Het is veel moeilijker om beelden van camera’s in de echte wereld te begrijpen vergeleken met games, die ontworpen zijn met makkelijk te herkennen beeldmateriaal voor menselijke spelers.”
Die mysterieuze zelfverbetering
Google claimt dat SIMA 2 zichzelf kan verbeteren, wat in de krantenkoppen als doorbraak wordt gepresenteerd. Maar hoe werkt dat precies? Het technische rapport laat nog op zich wachten, maar uit de schaarse informatie blijkt dat het vooral gaat om het verzamelen van speldata die gebruikt kan worden om de volgende versie te trainen.
Dat is vergelijkbaar met zeggen dat GPT-5.1 zichzelf verbetert omdat OpenAI alle gesprekken kan gebruiken voor GPT-5.2. Niet helemaal de radicale zelfverbetering die de berichtgeving doet vermoeden.
Ter vergelijking: eerdere Google-systemen zoals AlphaGo begonnen inderdaad met menselijke demonstraties, maar AlphaZero – de nog sterkere versie – leerde daarna volledig door zelfstandig te spelen. Die bewezen vorm van zelfverbetering is hier (nog) niet aanwezig.
Wat werkt wel?
De prestaties van SIMA 2 zijn zeker indrukwekkend te noemen. In Googles eigen metingen scoort het systeem ongeveer 65% op taakvoltooiing, waar mensen op 77% uitkomen. Dat is een verdubbeling ten opzichte van SIMA 1, die rond de 30% bleef steken.
Bijzonder is de test met Genie 3, Googles systeem dat compleet nieuwe 3D-werelden kan genereren uit een afbeelding of tekstprompt. Toen SIMA 2 in die nooit eerder geziene omgevingen werd gedropt, wist hij zich toch te oriënteren en instructies op te volgen. Dat laat zien dat de AI niet alleen patronen heeft geleerd, maar ook kan generaliseren naar nieuwe situaties.
De kinderziektes
Google geeft zelf eerlijk toe dat er flinke beperkingen zijn. SIMA 2 worstelt met complexe taken die veel stappen en tijd vergen. Zijn geheugen is kort – om de AI snel te houden, hebben de onderzoekers het langetermijngeheugen teruggeschroefd. En de bediening van toetsenbord en muis blijft lastig.
Waarom is dit belangrijk?
Stel je voor: over een jaar of twee draaien deze virtuele werelden in 4K in plaats van 720p. SIMA 4 of 5 heeft dan een geheugen van uren in plaats van minuten. Hij begrijpt vage instructies als “geef me dekking” in plaats van alleen “draai linksom”.
Google mikt duidelijk op de game-industrie, een markt van honderden miljarden dollars. En wie weet is de race tussen de release van GTA 6 en een échte generalist AI-agent die meespeelt wel spannender dan we denken.
Voor nu blijft SIMA 2 vooral een veelbelovend experiment. Maar de richting is duidelijk: AI die niet alleen opdrachten uitvoert, maar écht met je meespeelt. Of dat over een paar jaar ook in de echte wereld werkt met robots? Daar zijn de meningen nog verdeeld over. Maar voor gamers die een extra teamlid kunnen gebruiken, lijkt de toekomst in elk geval veelbelovend.

Meer upskilling nodig om adoptie AI te verhogen
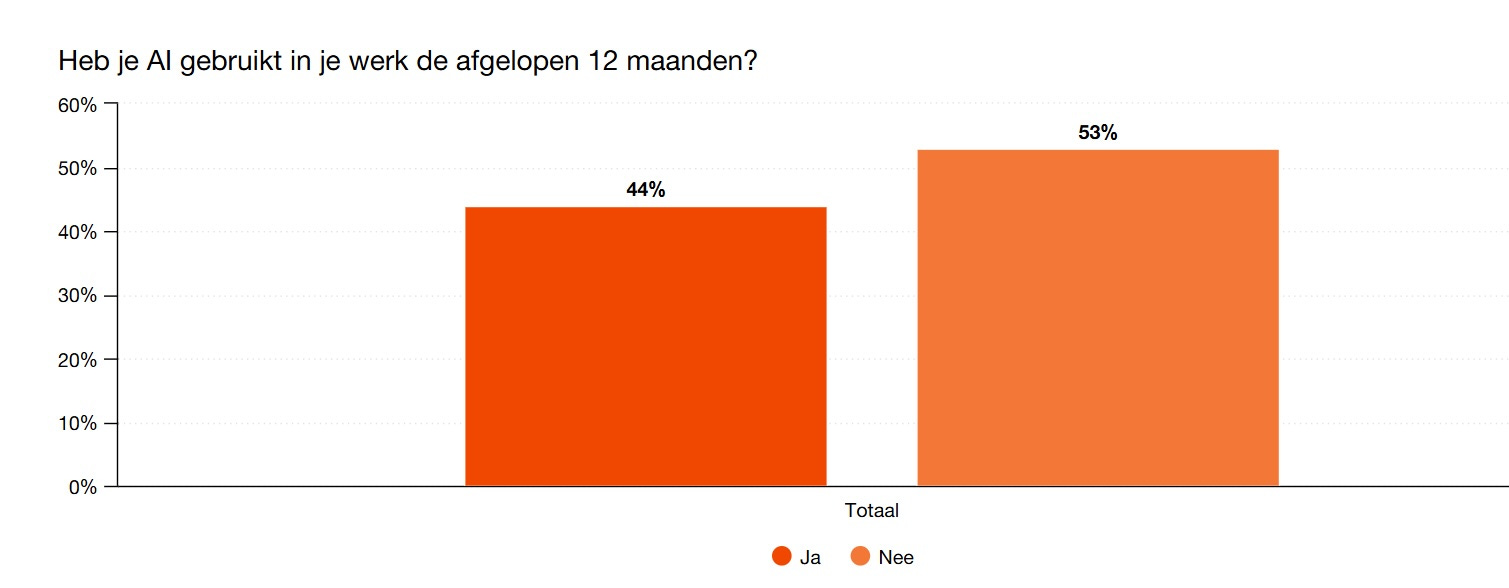
Nederlanders zijn over het algemeen enthousiast over en nieuwsgierig naar het gebruik van AI op hun werk. Tegelijkertijd gebruikte slechts 44 procent van de werknemers AI in het werk de afgelopen twaalf maanden. Ontdek hoe dat komt.
🔮 Prompt whisperer
GPT-5.1 onder de loep: zo haal je het maximale uit OpenAI’s nieuwste model
Vorige week kondigden we GPT-5.1 aan – OpenAI’s nieuwste model dat zonder veel fanfare de wereld in werd gestuurd. We beloofden je een grondige analyse, en die krijg je nu. Na uitgebreid testen van zowel de Instant- als Thinking-variant hebben we ontdekt wat dit model echt kan, waar het uitblinkt en – belangrijker nog – hoe je het optimaal inzet in je dagelijkse werk.
Wat krijg je vandaag?
Onze eerlijke review van GPT-5.1 Instant en Thinking (inclusief waar het nog steeds fout gaat).
De zes-stappen-aanpak die je resultaten 10x beter maakt.
Copy-pasteprompts voor schrijvers, developers en ondernemers.
Waarom OpenAI géén benchmarks deelde (en wat dat betekent).
Het geheime wapen van metaprompting dat je blinde vlekken blootlegt.
Hoe je voorkomt dat ChatGPT een hielenlikker wordt.
